
1. 머신러닝의 학습 프로세스
머신러닝의 기본 도형

머신러닝을 통해서 우리는 예측치를 얻을 수 있죠.
가지고 있는 데이터 x를 학습하여 생성한 함수가 바로 f이에요. y에 넣으면 그 결과로 예측치 f(.)를 생성해요.
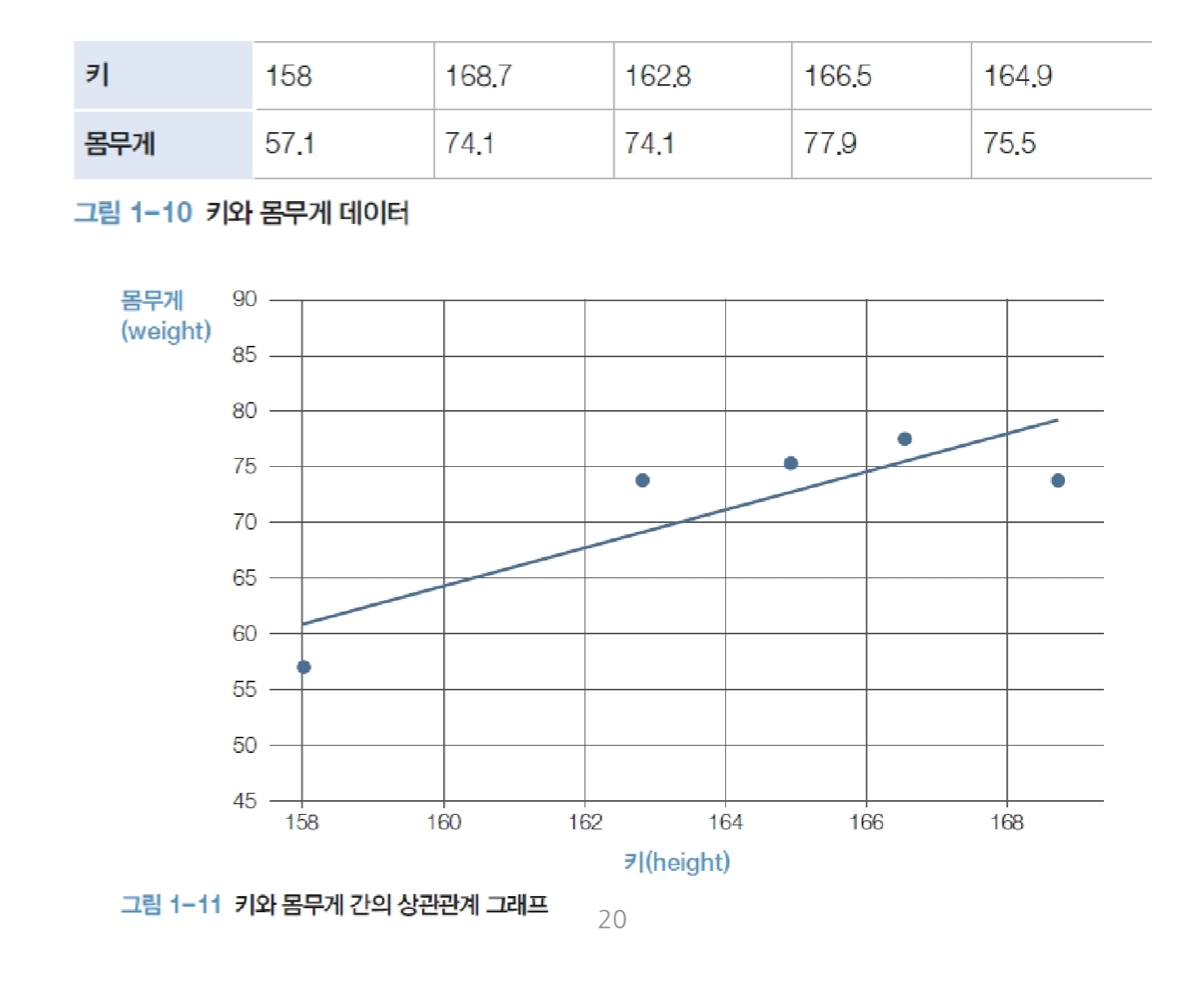
이러한 함수를 얻기 위해서는 데이터 x 가 필요하죠. 위의 키와 몸무게에 대한 데이터가 5쌍이 있어요.
이를 기준으로 우리는 키와 몸무게에 대한 상관관계를 일차함수로 표현할 수 있게 됩니다.
상관관계를 식으로 표현하는 것을 바로 모델 (model)이라고 해요! 그리고 이러한 모델을 찾는 과정을 모델링(modeling)이라고 합니다.
어떤 모델이 키와 몸무게의 관계로 가장 적합 (fitting)할지는 모르지만, 위의 데이터를 기반으로 가장 알맞은 함수를 찾을 수 있게 됩니다.

위의 식은 일차함수를 나타낸 식이에요. 위의 알파와 베타 값이 가장 알맞은 수를 찾으면 새로운 키에 대한 몸무게를 예측할 수 있게 되는 것입니다! 그럼 머신러닝 프로세스를 한 번 정리해볼까요?
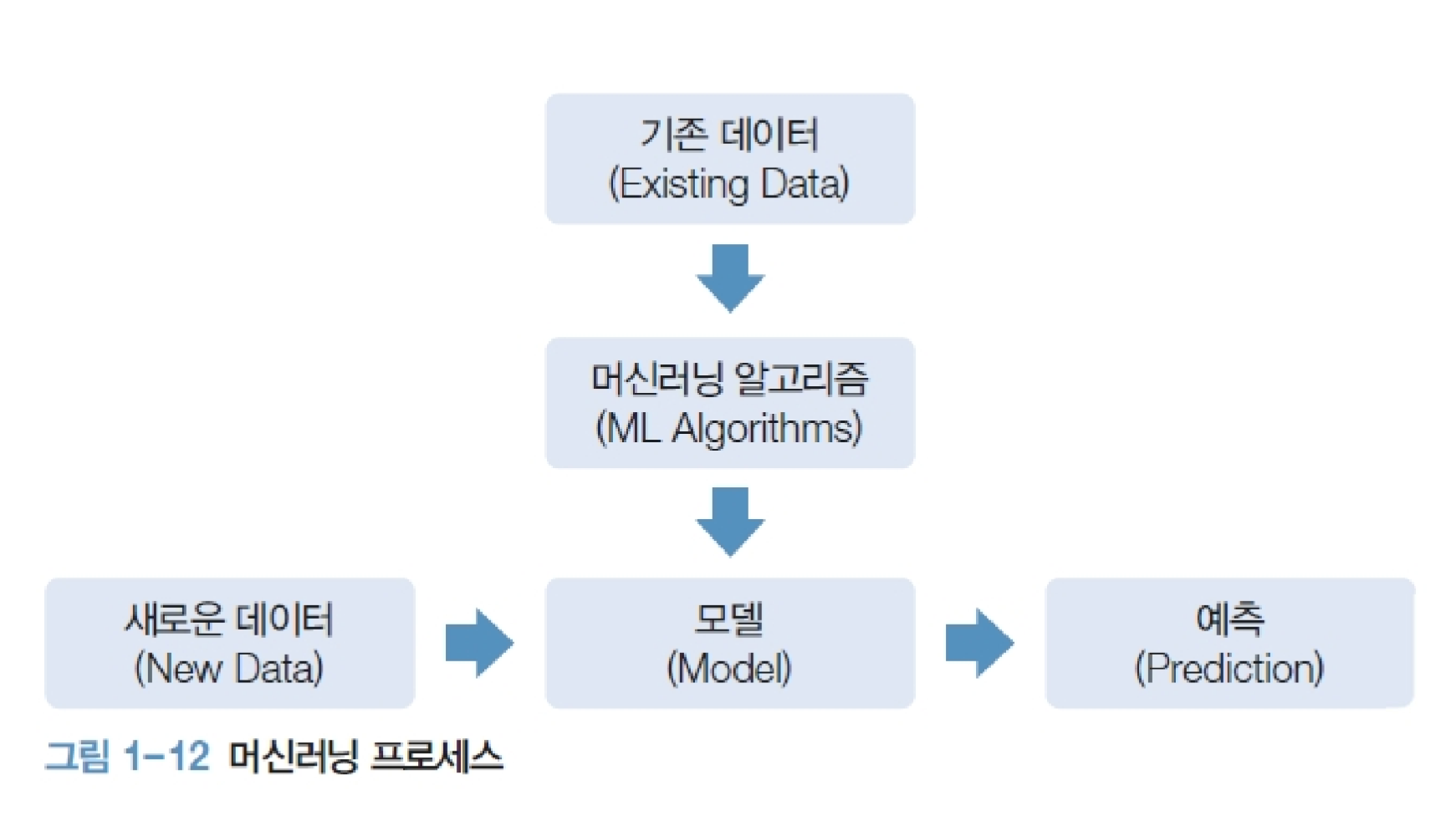
기존 데이터를 활용한 머신러닝 알고리즘을 통해 모델을 만듭니다. 이를 가지고 새로운 데이터를 통해 예측을 할 수 있게 되는 것입니다! 아니, 근데 머신러닝 알고리즘이 정확히 뭐일까 궁금하실 수 있어요. 바로 이 함수는 찾는 방법이라고 생각하시면 돼요. 이제 함수 즉, 모델을 찾는 방법에는 어떤 것들이 있는지 한 번 알아볼까요?
2. 머신러닝의 종류
1) 지도학습와 비지도 학습
머신러닝은 실제 답의 존재 여부에 따라 크게 지도학습(supervised learning) 과 비지도학습(unsupervised learning) 으로 나뉩니다.
쉽게 이야기 하자면, 지도를 받냐 안 받냐에 따라 분류가 되는 겁니다. '이런 말랑한 코를 가진 아이들을 강아지로 분류해야해!'라는 예시를 주면 이를 컴퓨터가 학습하는 것이죠. 하지만 비지도 학습은 도움없이 컴퓨터가 스스로 학습하며 데이터들 간의 규칙성을 찾아내요!
| 머신러닝 대분류 | 머신러닝 종류 | 설명 |
| 지도학습 | 회귀 | 연속형 값인 y의 특징을 기반으로 데이터 x를 이용하여 예측 |
| 분류 | 이산형 값인 y의 특징을 기반으로 데이터 x를 이용하여 예측 ( 이중분류, 다중분류로 종류가 또 나뉘어짐 ) |
|
| 비지도학습 | 군집 | y값이 주어지지 않고, 데이터 특징이 유사한 값들의 모임을 군집으로 표현하는 기법 |
회귀 vs 분류 vs 군집
이 세가지 종류를 쉽게 구분하는 방법이에요!
원하는 예측값이 있는데 이게 연속값이야? (키, 몸무게) ➡️ 회귀
원하는 예측값이 있는데 이게 이산값이야? (성별) ➡️ 분류
원하는 예측값이 없는데 그룹으로 묶어야 해? ➡️ 군집
2) 이 외의 종류
이외에도 강화학습과 생성이라는 종류가 존재합니다. 이 아이들은 지도학습와 비지도 학습의 중간에 해당하며 양쪽의 특성을 모두 가지고 있어요.
| 머신러닝 분류 | 설명 |
| 강화학습 (reinforcement learning) |
컴퓨터가 세상에 존재하는 규칙을 스스로 시뮬레이션 하면서 게임처럼 규칙을 학습 |
| 생성(generation) | 세상에 존제하는 규칙을 학습한 모델이 존재하지 않는 새로운 모델을 창조 ( 비지도 학습에 조금 더 가까워요 ) ex. chatGPT, AI 프로필 |
'데이터 > 데이터 사이언스 및 분석' 카테고리의 다른 글
| [캐클 입문] 타이타닉 생존자 예측하기 (전처리부터 예측까지) (1) | 2023.12.17 |
|---|---|
| [ 데이터 분석 마스터 ] #1. 머신러닝 톺아보기 (feat. 추천 알고리즘) (2) | 2023.10.24 |

